Project Detail /
Self-Distillative Exemplar Replay for Incremental Drug Identification
A deep-learning-driven recognition pipeline for medication safety, designed to retain prior visual knowledge while learning newly added drug classes.
01. OVERVIEW
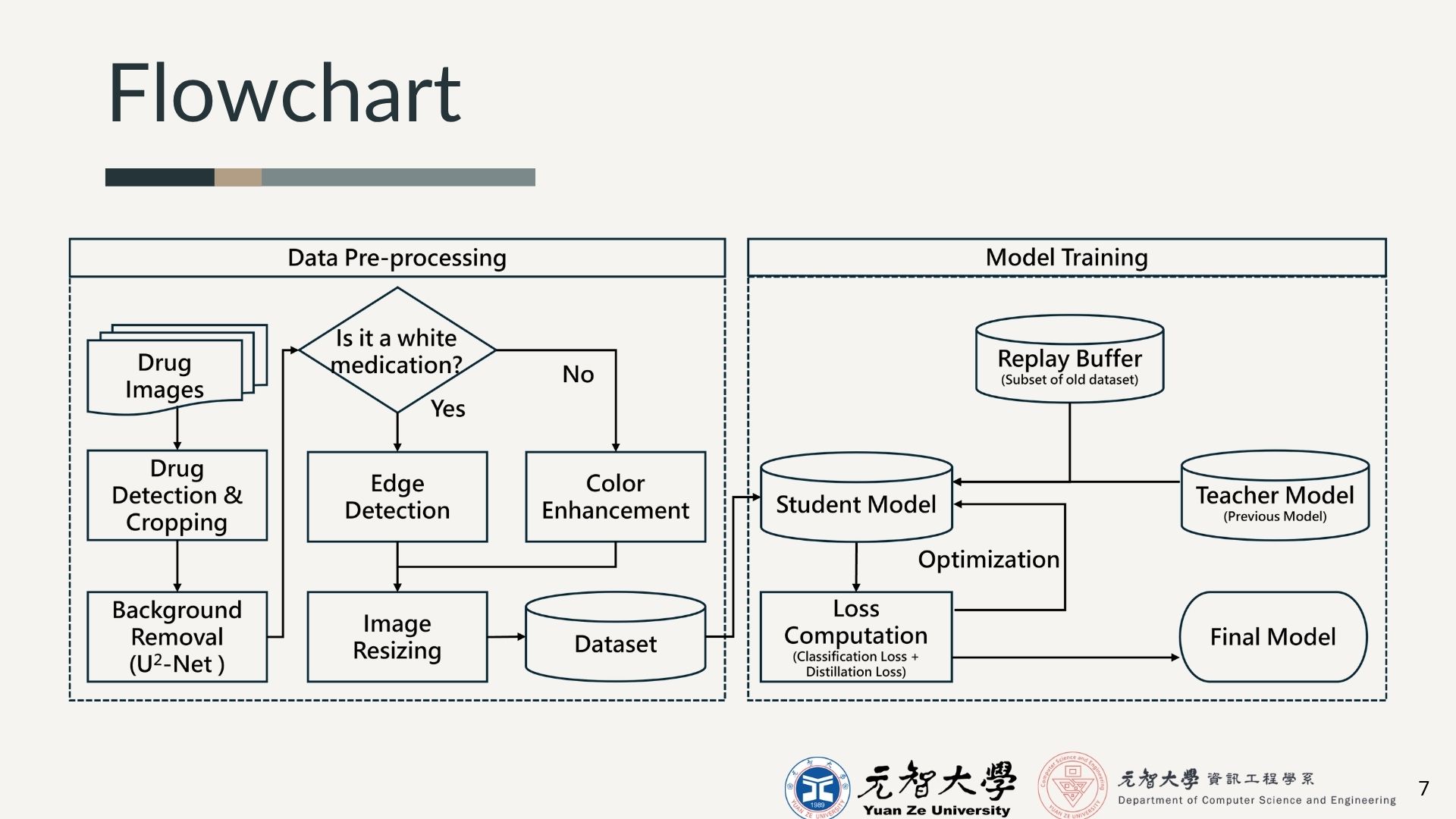
This project addresses catastrophic forgetting in incremental drug identification. The proposed framework enables models to absorb new medication classes without sacrificing performance on previously learned ones.
By integrating self-distillation with exemplar replay, the system preserves representative memory samples and distills historical decision boundaries, ensuring high-fidelity recognition in dynamic clinical environments.
02. PROBLEM_AND_APPROACH
Problem
Catastrophic Forgetting
Traditional fine-tuning on new medication categories causes a rapid decline in recognition accuracy for previously learned classes.
Approach
Self-Distillative Exemplar Replay
The framework preserves a fixed budget of representative memory samples while using soft-target supervision to distill historical decision boundaries into the updated model.
03. KEY_RESULTS
99%+
Average Recognition Accuracy
-1.75%
Forgetting
04. PROJECT_CAROUSEL




05. EXPERIMENT_TABLE
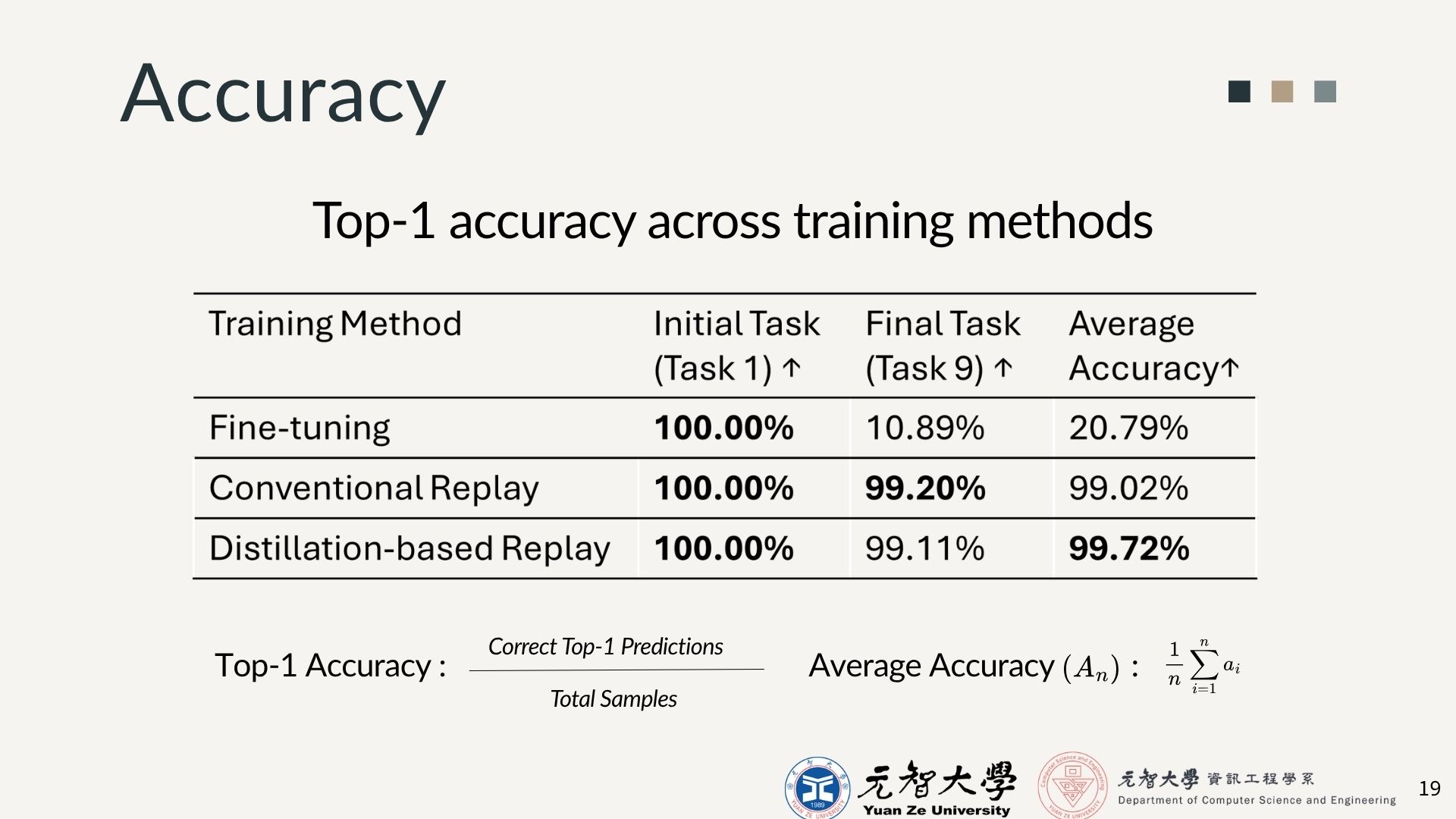
TABLE_A / Top-1 Accuracy across Training Methods
| Training Method | Initial Task (Task1) | Final Task(Task9) | Average Accuracy |
|---|---|---|---|
| Fine-Tuning | 100.00% | 10.89% | 20.79% |
| Conventional | 100.00% | 99.20% | 99.20% |
| Distillation-based Replay | 100.00% | 99.11% | 99.72% |
TABLE_B / Comparison of Continual Learning Metrics Across Training Methods
| Training Method | Forgetting Measure | Forward Transfer | Backward Transfer | Note |
|---|---|---|---|---|
| Conventional | 0.0375 | 0.94375 | -0.0375 | FT Baseline = 1/20 = 0.05 |
| Distillation-based Replay | 0.0175 | 0.95 | -0.0175 | Best overall balance |
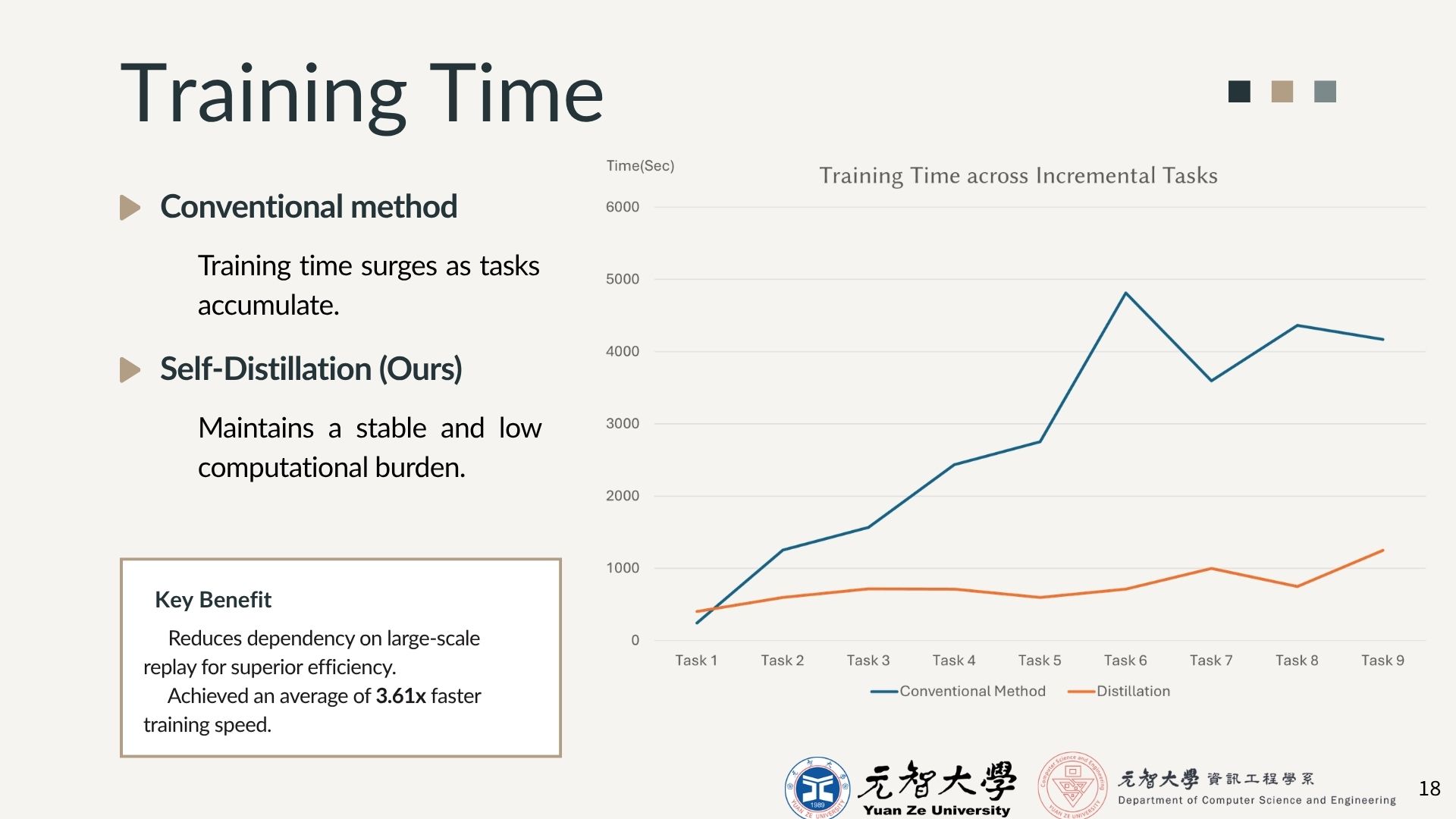
06. PERFORMANCE_CHARTS
Training Time across Incremental Tasks